
Comic vine api letting you down? Let my cache let you down instead!
Using the cache
In ComicTagger you head over to File -> Settings (or CTRL+Shift+S) and set the following:
API Key:
a782f254-341f-49cb-bada-6d6343652d5c
API Url:
https://cvcache.titor.dev/api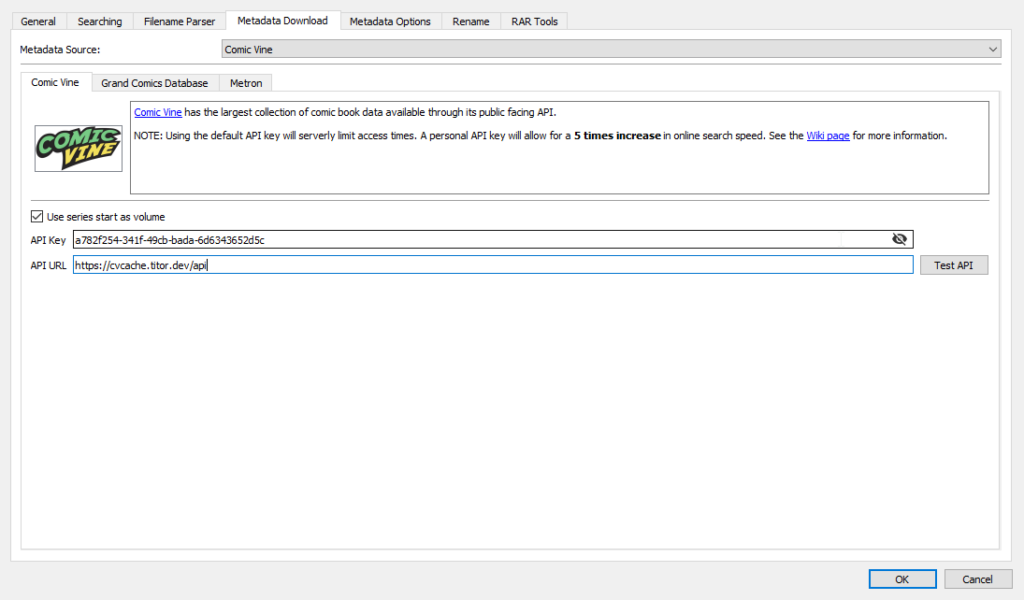
You can then start tagging comics with no rate limit!
What if it goes down?
As right now only I and about 2 other people use it, this is on a Raspberry Pi with limited resources available to it. If people find a need for it, this can be upgraded.
You can open an issue on Github(fastest), message me on Discord, X, leave a comment here, and I will get it back up or on its own Raspberry Pi/a better server.
Can I get a sql export?
Yes! This is in postgreSQL, but I can work on converting the export to whatever is needed, just let me know! Keep in mind this is not very optimized right now, there might be some data duplication inside it.
Why are you hosting this?
There’s alternatives to ComicVine like Metron, but according to more knowledgeable people than me there’s still more data available on ComicVine.
The draconian ComicVine rate limits make it impossible to tag any library of comics. Even a single long-standing comic such as Spider-Man is impossible. What’s worse, ComicVine will likely die. Maybe not in a year or five, but preparations have to be made for its replacement.
I believe, given the current rate limits, there should be a community effort to cache as much data from ComicVine as possible and submit it to Metron as well as to educate current ComicVine contributors to contribute to Metron instead.
My cache isn’t anywhere near ready for this, but the plan is to have trusted cachers(or cacheers as I like to call them) contributing to the same database with their own caching servers and keys.
How old is the data?
The Titor cache is not up to date with Comic Vine. This has been running for months as I have been tagging some odd thousands comics. There is a way to refresh data, but only manually by sending a query parameter, but no metadata software currently allows this, making it impossible unless you’re a developer. Scratch that, the amazing lordwelch added this as an option in comic tagger after I was daydreaming on the Mylar discord about wanting to implement this myself in a customized version of it.
There might be some 2024 comics with missing metadata, so you can now use my cache with comictagger and refresh it when you need to!
Should I refresh for older comics? Could there be new metadata?
Highly unlikely. I am insanely paranoid, and before using this on my actual comics I made a copy of my entire library, removed the tags from all of it and painstakingly re-tagged everything using my cache.
I have not found a single issue(ha!) or metadata change in thousands of comics tagged a year prior. I made a small python script to go through all the comicinfo.xml’s and compared them between libraries. The data was identical.