

ArchiveBox is a powerful, self-hosted internet archiving solution to collect, save, and view websites offline. Install Archivebox in just a few minutes using docker!
The Internet Archive is an amazing website, but there are a few caveats:
- All saved URLs have to be public
- It cannot save all types of content
- It does not archive at any depth, meaning a forum post with 100 pages needs every page submitted individually
- Storing results for offline use is difficult, especially when you need possibly hundreds of archives for researching a single topic
- Archives can be taken down at the request of the owner
- Archives can be taken down by bogus legal requests
- A single centralized place for archiving is dangerous, even the Great Library of Alexandria fell. See the latest lawsuits too
Docker and Portainer
If you don’t already have them, install Docker and Portainer following my guide.
Installing ArchiveBox
Your exact configuration will depend on your needs. This configuration assumes this is going to run on a local network for personal, local archiving purposes only. It requires an admin account to login, create and view archives.
-
Open Portainer and create a new stack

-
Paste the following YAML in. Change your volume path and anything else you need
YAMLversion: '3.9' services: archivebox: image: archivebox/archivebox:0.7.2 command: server --quick-init 0.0.0.0:8000 ports: - 8000:8000 volumes: - /volumes/archivebox/data:/data environment: - ALLOWED_HOSTS=* - PUBLIC_INDEX=False - PUBLIC_SNAPSHOTS=False - ADMIN_USERNAME=${ADMIN_USERNAME} - ADMIN_PASSWORD=${ADMIN_PASSWORD} - PUID=911 # If you encounter permission issues, change this to the UID on the host, possibly 1000 - PGID=911 # If you encounter permission issues, change this to the GID on the host, possibly 1000 - MEDIA_MAX_SIZE=750m - TIMEOUT=120 - CHECK_SSL_VALIDITY=False - SAVE_ARCHIVE_DOT_ORG=False - PUBLIC_ADD_VIEW=False # Change this to true for the browser extension to work, though make sure not to expose it on the internet. Use Wireguard instead!


-
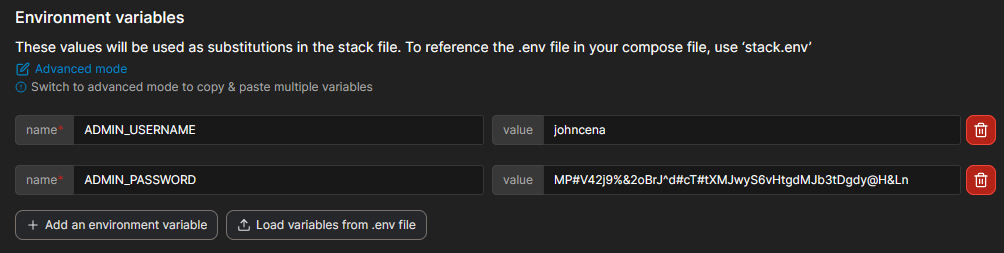
Add two new environment variables named
ADMIN_USERNAMEandADMIN_PASSWORD, fill them in, then you’re ready to Deploy the stack!


Using Archivebox
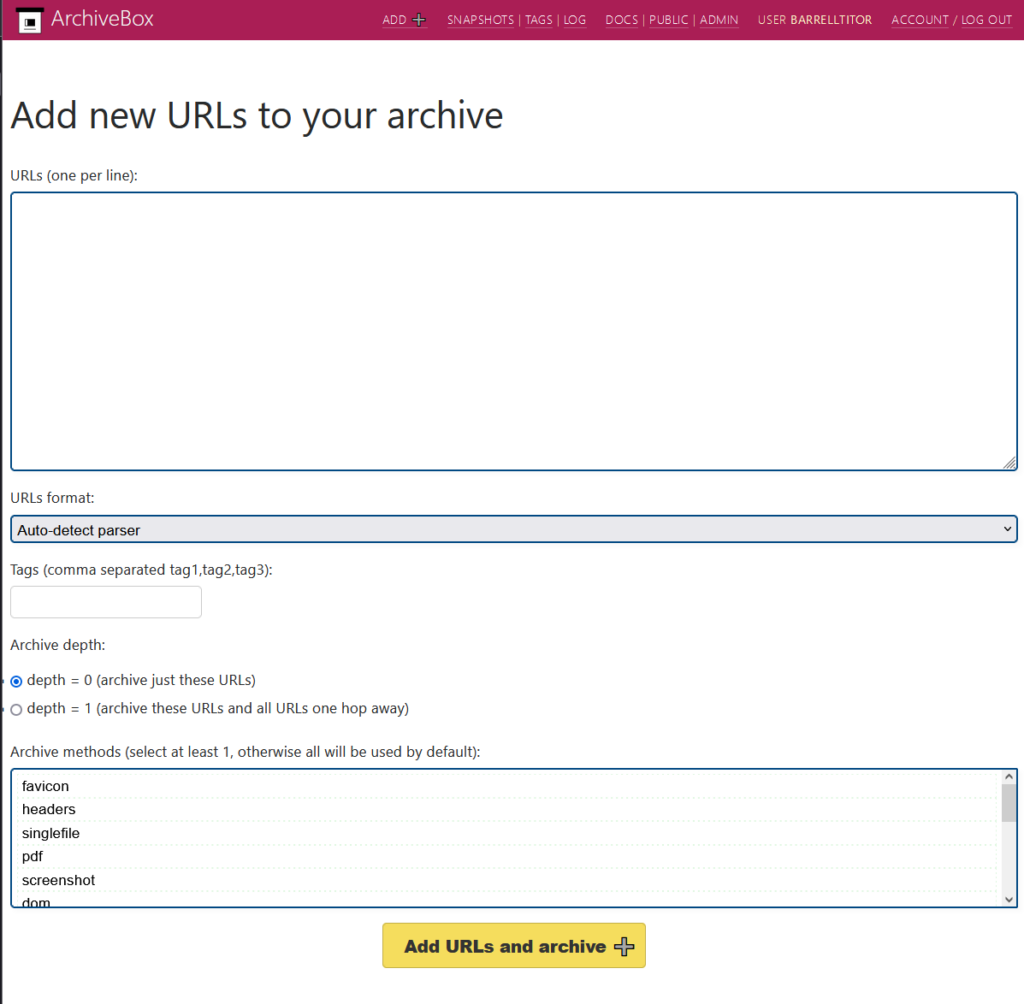
After you log in, you can start archiving! Click on the Add button at the top and paste in your favorite URLs. Let’s say you want to archive a tweet from Obbe Vermeij. You will need to:
- Paste the URL in the big white text input box
- Click the big yellow button at the bottom
That’s it, now it’s archiving!
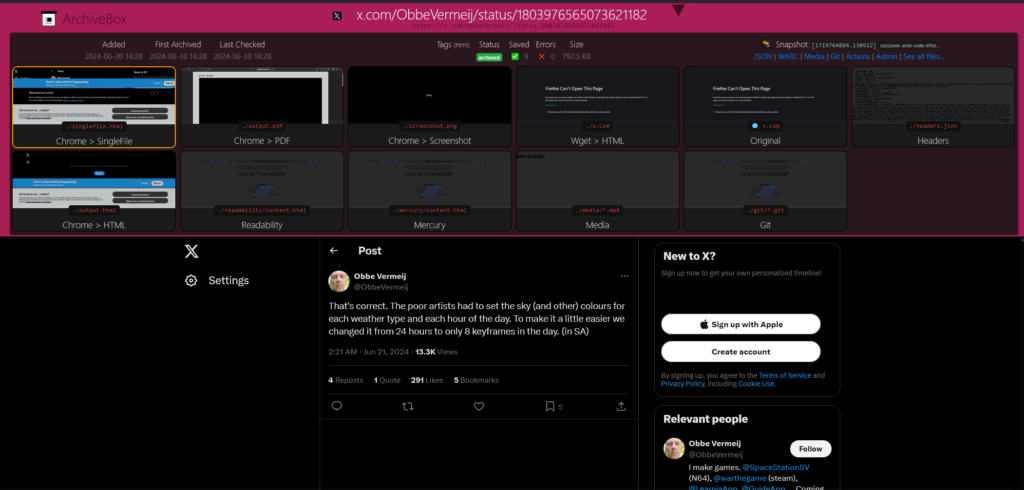
Options and caveats
Depth
I really like the depth feature. This can technically allow you to archive forums, but there is going to be an incredible amount of wasted space due to lack of deduplication as many files are going to be identical. Unless your file system accounts for this, you might want to use rdfind to replace them with hardlinks.
rdfind -makehardlinks true -removeidentinode false -checksum sha256Cookies and user agents
You can also use your own cookies and useragent! Just add these environment variables:
- WGET_USER_AGENT=${AGENT}
- CURL_USER_AGENT=${AGENT}
- COOKIES_FILE=/data/cookies.txtRegex
You can also use a regex deny list to avoid archiving certain websites by URL. The environment variable is
- URL_DENYLIST=${REGEX}Here’s an example regex I use:
^http(s)?:\/\/(.+\.)?(youtube\.com|facebook\.com|amazon\.com|twitter\.com|instagram\.com|tiktok\.com|tumblr\.com|deviantart\.com|myanimelist\.net|phpbb\.com|phpbb\.net)\/.*$|(\.(css|js|otf|ttf|woff|woff2|gstatic\.com|googleapis\.com\/css)(\?.*)?$)|^.*\/forum\/(ucp|viewonline|index|viewforum|posting|search).php.*$|^.*#p[0-9]+$|^http(s)?:\/\/www\.kanzenshuu\.com(\/)?$In regex, a | means “or”, so if you want to add another site you just put a | at the end and add a new regex. For example, if you want to never archive my blog you can add in
|^http(?:s)?:\/\/.*titor.dev.*$Let’s break this down!
^ – Beginning of the linehttp – literal characters “http”(?:s)? – optional s after http for https sites. The ? at the end makes it optional. The () make it a group to separate it from the “http” part, and the :? makes this group non capturing. This last part doesn’t matter much here, but it’s good practice to do it if the group is there just to separate some characters and make them optional:\/\/ - this is just ://. Slash is a special character, so you need to escape it with a backslash. .* – the dot means any character, and the asterisk means any amount of times (until titor.dev)$ – end of the line
So now you know a bit of regex too! You can identify the start and end of the line with ^ and $, you know how to make part of your match optional in case text might be there, and wildcard match any character! The sky is the limit for you now.
You should always use https://regex101.com/ for exact explanations on what a regex does, and easy testing!
Browser Extension
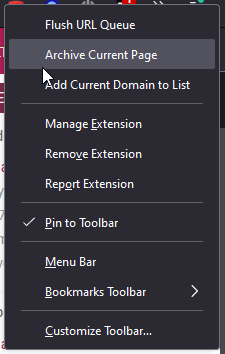
You can use this extension to manually and automatically submit URLs to the archive.
To do this manually, right click on it and use the option from the context menu.
To add it automatically, add the domain to the list from the context menu, or from the extension’s settings
Leave a Reply